這系列文章的開端,必須要講一下兩個有關演算法的專有名詞,分別是時間複雜度(Time Complexity)和大O記號(Big O Notation),雖然是兩個名詞,但實際上是同一個概念,那便是「該如何描述針演算法的速度」呢?
如何形容程式的效能
首先要祛魅在遊戲圈一個非常氾濫的錯誤觀念,那便是「CPU 效能被榨乾」,每當出現比較複雜的場景時,很多玩家都喜歡說這句話,但實際上CPU的效能根本不可能被榨乾,因為同一個型號CPU的運算一單元的速度必然是均等且不變的,並不存在什麼「畫面有越多東西,CPU就跑越快」,無論是計算一加一等於多少,還是要計算角色的行為樹,同一型號的CPU都是在以一樣的速度在完成這些計算。那撇除硬件配備的差異,還有什麼東西導致了有些程式要花費更多時間運算,有些則花更少時間運算 ? 其答案的關鍵是CPU操作的次數。
為什麼運行時間不能用來比較演算法?
一段運算的快慢取決於兩大因素,一是這段運算的操作次數,二是硬體差異。如果用運算所需時間來描述一個演算法的優劣,那必然會非常混淆 ,例如有一段運算太慢,那究竟是因為操作次數還是硬體而導致的 ? 因此,我們最好別用運行時間來評比一個演算法的優劣,但我們又不可能把操作次數和硬體差異這兩個完全不同的次元的概念放進同一個標準裡,那不如我們就要先摒除開發者難以決定的部分,也就是程式所運行的硬體配置,把我們的注意力放在另一個部分,即其操作次數。
但問題又來了,一個演算的操作次數會受數據數量影響,例如我要在書堆裡找一本書,那書堆數量的總數就會影響我找書的效率,書總數越多,我就越慢,而用不同的方式去找書也會影響找書的效率,假如,書堆已經被排列以編號好了,那只要找編號便可以立馬找到目標的書,這就和我一本一本書翻開來找快非常多,在不同的背景下,使用不同的手法,完成目標的操作次數都是不一定。因此,要描述一個演算法的操作次數,並不能單純使用一個整數,例如幾步幾步。我們要用更複雜更立體的方法來描述,那便是「時間複雜度(Time Complexity)」,時間複雜度簡單而言是一個函式,需要輸入一個數據數量的參數,最後就能得出該演算法運算所需要的操作次數。當然這個函式並不會真的拿來計算結果,通常只是以函式的形式來描述一個演算法所需要的操作次數。
時間複雜度應該如何表達? 什麼是大O記號?
大O記號的數學原意 :
要了解時間複雜度就必須要認識大O記號(Big O Notation),大O記號是一個經典數學符號,也有被叫做「漸近符號」。
最一開始大O記號和演算法分析並沒什麼關係,它是Paul Bachmann在他1894年出版的的書《Die analytische Zahlentheorie》裡提出的一系列函式,它們是專門用來描述一個單一參數的函式,當這個參數內的變數逐漸趨近無限大之過程中,會有的不同行為模型。通常這個函式會被定義為O,而該函式裡的參數也是一個函式,被定義為f,而函式f的參數則會被定義為n,是一個會逐漸趨近無限大的變數,完整的寫法是O( f( n ) )。而函式f是行為模型改變的關鍵,當n不停增加直至無限大為止,不同的函式f便會導致完全不同的數據走向。
下圖是一系列的大O記號函式的圖像化,可以大概感受一下不同的數據走向是什麼意思。
同樣都是n趨近無限大,但在使用不同f(n)的情況下,很明顯的,有些線坡度更高,有些則更低。
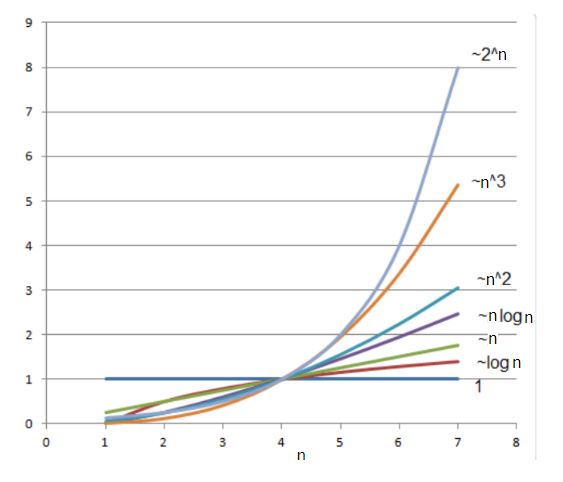
大O記號的實際應用 :
到後來史丹佛大學的Donald Knuth在論文《BIG OMICRON AND BIG OMEGA AND BIG THETA》裡利用Paul Bachmann提出了大O記號來描述演算法的效率,而當中的變數n則被代入為演算法應用在的數據容器內的物件總數。根據《BIG OMICRON AND BIG OMEGA AND BIG THETA》所述,Donald Knuth原本其實想用Ω記號(Omega Notation),但有趣的是作者找了半天沒找到可以用的範例,最後才找到了Paul Bachmann提出的大O記號。至此大O記號也才和演算法分析聯繫在一起,便成為了時間複雜度最經典的描述方式。
但這裡聲明一下,以上的內容是參考多篇文章,整合而成的一個比較合理的故事版本,如果可以的話,我想翻翻原着以查證一下,但我暫時還真沒找到《Die analytische Zahlentheorie》的英文譯本,如果你直接搜書名或英文翻譯的書名可以找到其pdf檔,但基本上都是德文版本,看看哪天我找到了我看得懂的譯本,或者哪天我學了德文再詳細查證一下,暫時知道個大概就可以了。
時間複雜度的實際應用
接下來我們來介紹幾個常見的大O記號。
時間複雜度A O( 1 ) :
O( 1 )是非常常見的時間複雜度,
簡單而言,操作次數不會因為數據量增多而改變,
無論數據量有多少,也只需要一個步驟便能完成的運算。
一般會被認為是最理想的時間複雜度。
例子:
- 一樣以書堆為例子,如果我們這裡有一到六集的沙丘由小至大、左至右排列整齊,那想取得最早的一本小說便直接拿起最左的一本小說便可,只需要一個步驟就能完成,那無論Franklin Herbert的兒子拿他爸的IP亂寫了幾百本續集,執行者也只需要一個步驟就能完成。
- 同樣以書堆為例,如果每一本書都以編號排列並以編號向着執行者,那只要執行者知道目標書本的編號,然後只需看一眼書本的編號便知道哪一本小說是在尋找的集數。
時間複雜度B O( n ) :
O( n )指的當我們有n個數據,就需要n個步驟才能完成運算,
簡單而言,步驟數量會因隨着數據數量增加,步驟數量和數據數量會呈正相關。
由於運行效能嚴重被數據數量影響,因此是比O( 1 )差上不小的時間複雜度。
例子:
- 以小說為例,如果執行者不知道Franklin Herbert老頭子在出完第六集沙丘就駕鶴西歸,
並且書也沒做整理,但執行者想知道書堆中沙丘正傳最大的集數是多少,那執行便必須要一本一本翻查,並且在小本本( 記憶體 Ram )紀錄下最大的集數,等執行者最後翻完n本書才會知道最大的集數是多少。
時間複雜度C O( log n ) :
O( log n )指的當我們有n個數據,就需要大概log(n)的步驟才能完成運算,
簡單而言,操作次數和O(n)一樣會隨着數據數量增加而提高,步驟數量和數據數量一樣會呈正相關。
但不同的地方在於數據數量每增加1,步驟數量是以對數方式成長,其操作次數增加的量不會多於O( n )增加的量,
因此O( log n )是當O( 1 )無法被實現時,相比O( n )有效率的時時間複雜度
例子:
- 同樣以小說為例,如果5000本書堆中的其中一本書失竊了,只剩下4999本小說。
但書堆的主人擔心他最愛的第四集《沙丘神皇》還在不在,
因此他請執行者去檢查。所倖的是所有小說都以書本的ID排列好。
但在這個情境下,如果只是一本一本翻,其實效率不會提高,因此需要一個特殊找法,
執行者可以用「終極密碼」的方式把4999本小說二分再二分,來找到目標書本。
這做法比一本一本翻開來看顯然更有效率,但也遠不如O( 1 )那般有效能。
可以從這幾個例子看到,當我們用大O記號來形容演算法時,
其實不是在討論的不是演算法的快慢,
而是在討論數據數量和操作次數的關係,
當f(n)越大,操作次數越受數據數量影響,
反之,當f(n)越少,操作次數越不受數據數量影響。
以下是是一幅描述大O記號的曲線圖,在此用來系統化性寫一下大O記號常見的不同模式以作補充。
| 當 函式f | 時間複雜度 | 實例 | 效能 |
|---|---|---|---|
| f(n) = 1 即O(1) | 不論數據容量有多少個物件, 完成運算的步驟都是常數, 不會因數據容量數量改變而增加。 | 雜湊表 插入或移除 元素 | 最優 |
| f(n) = log n 即O(log n) | 隨着數據容量內物件數量增加, 完成運算的步驟數量也隨之增加, 但步驟增加幅度小於物件增加幅度。 | B-Tree 插入或移除 元素 | 普通 |
| f(n) = n 即O(n) | 隨着數據容量內物件數量增加, 完成運算的步驟數量也隨之增加, 但步驟增加幅度等於物件增加幅度。 | 陣列 移除元素 | 較差 |
| f(n) = n^2 即O(n^2) | 隨着數據容量內物件數量增加, 完成運算的步驟數量也隨之增加, 但步驟增加幅度遠大於物件增加幅度。 | 較少見 | 最差 |
總結
簡單總結一下,當我們看見有人說這演算法或數據結構是O(1)的時候,那這個演算法或數據結構必然運作的非常快速的,而如果有人說這演算法或數據結構是O(n)的話,那就要考慮一下其性能問題了。但要留意,並不是O(1)的數據結構就是最好的數據結構,還是要根據數據結構的特性來決定使用哪一種數據結構,像記憶體使用的多寡等,但這就是後話了。
而當有人問你寫的這段代碼快嗎,效能好嗎,這時候你就別簡單的告訴他「快」,
你可以說「我寫的這段代碼都是用時間複雜度O(1)的演算法,我相信能滿足大多數情況的使用。」,
一瞬間專業感爆漲。
除了上述提及過的大O記號外,其實還有不少其他類型的大O記號可以用描述演算法優劣,
但礙於篇幅問題,在此不多作過多闡述。
而最為基礎對時間複雜度和大O(記號)就先說到這裡,這概念在之後其他數據結構和演算法的文章也會經常用到。
核心摘要 ( Takeaway )
時間複雜度 : 一個演算法所需要操作次數的抽象化形容。
大O記號 : 一種函式用來描述一個單一參數的函式,當這個參數內變數逐漸趨近無限大之過程中,會有的不同行為模型。
發佈留言