亂數在遊戲開發中是十分重要的一環,
為了使遊戲的內容更不可預測,大多遊戲開發都會在設計上加入亂數來控制各項參數,
大的有像Mineraft那樣的隨機地圖生成,小的有像每個NPC的行為模式等。
關於每個NPC的行為模式的例子,我也不太確定能不能公開談太詳細,
但像先前被泄漏的GTA V源代碼裡就可以看到遊戲裡每個NPC其實都有一個隱藏且隨機的勇氣值,
而這個勇氣值就會決定不同NPC面對玩家的危險行為有什麼反應,
例如,高勇氣值的NPC會拿起槍反擊,而低勇氣值的NPC則會溜之大吉,而有些則會報警。
試想想遊戲裡的NPC所有人對玩家的反應都相同的話,整個世界會多死氣沉沉,
可以說亂數充斥着遊戲源代碼的各處,也是開發過程的關鍵之一。
然而這簡單的兩個字「亂數」,其實並沒有看上去那麼簡單。
亂數只是一個抽象化的詞彙,
所謂的亂數也有分成不同分佈的亂數,以及不同實現亂數的途徑,
而這些不同的變因也使這些不同種類的亂數有不同的使用情境。
在這篇文章會先簡介一下幾個常用到亂數的分佈類型,作為這個主題的引言,
未來有時間再擴展一下關於實現亂數的方式,畢竟那方面的內容要翻一翻資料才行。
連續型均勻分佈(Continuous Uniform Distribution)
這種分佈模式是最常見、且最多人認識的的一種亂數分佈,
簡單一句就是毎一種結果的出現機率相同的亂數,
像擲骰子就是一種「接近」均勻分佈的亂數。
例如 : 變數 x 為 1 – 6 之間的隨機數字。
當我們重複生成 x 亂數 100000次後,1 至 6 的所有數字出現次數都應該是無限接近 100000 / 6次。
而為什麼我會說這是最常見、且最多人認識的的一種亂數分佈,
是因為大多數程式語言裡標準函式庫的亂數都是以均勻分佈生成的。
譬如 C++ 裡的 std::rand() 就是 0 至 2147483647的均勻分佈下生成的隨機亂數,
python 裡的 random.random() 則是由 0 至 1 浮動小數點的均勻分佈下生成的隨機亂數,
以及C#裡的 Random()、javascript 裡的 Math.random()都一樣是均勻分佈。
高斯分佈 / 常態分佈 Gaussian Distribution / Normal Distribution
雖然均勻分佈在電腦科學中是比較常見和常用的亂數分佈型態,
但回歸到現實層面上,絕大多數的隨機的數據其實都不會是均勻分佈的,
例如人的身高,成年人的身高有紀錄以來的最低身高是 54.6 cm ,最高則是272.0 cm,
我們可以得出一個簡單的結論,成年的身高分佈是54.5 cm 至 272.0 cm ,
如果人的身高是以均勻分佈,那身高 60 cm 、 身高 250 cm 的人數量會和身高 160 cm 的人數量相同,
除此之外,樹的高度、文首提到的勇氣值等等的隨機值也不可能是均勻分佈,
否則亂數的結果很顯然會不符合我們的一般人的生活經驗。
因此,如果我們如果想要在遊戲裡重現剛才提到的這些數據,
便不可能用均勻分佈的亂數來實現,而我們需要的便會是常態分佈,
常態分佈這玩意,應該大多數人在學校都有學過,但應該大多數人都不太清楚如何在編程上使用它,
常態分佈是基於中央極限定理(Central Limit Theorem CLT)推敲出來的一種分佈型態,
或者說是數學家發現了常態分佈的存在,然後再用中央極限定理去解釋它也可以。
如果要往深的聊,可以聊的非常深入,我光是在SPRINGER NATURE上搜 Central Limit Theorem ,
就有137, 099篇文章,而且都蠻長的,
可以說CLT在機率學裡應該算是一個不小的Topic,如果真要談的話,一定會錯漏百出,
而最早提出CLT的書是「The Doctrine of Chances or a Method of Calculating the Probability of Events in Play」,
有興趣的可以了解更多,網路上都有合法免費的pdf版本可以下載。
那我們在這裡只需要了解一件事情,
就是當一個事件中發生時隨機變數的數量越多,
越接近極端值的結果出現機率就會越低,而那就是常態分佈。
但為什麼會這樣呢 ? 以實務的例子說明會更好理解。
在這裡我們一樣以擲出骰子作為範例的事件,而擲出的骰子數量是這個事件中隨機變數的數量。
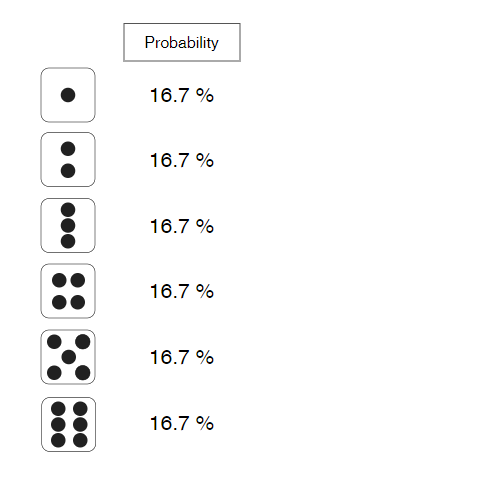
當我們只用一個骰子時,點數的最小值會是1,最大值會是6,
擲出的點數結果的所有可能性機率理論上都會無限接近於 1 / 6 ( 16.7% ),是均勻分佈。
但當我們改用兩個骰子的話,點數的最小值會是2,最大值會是12,
擲出的點數結果的所有可能性機率就不會是均勻分佈,
點數結果越接近最小值2或最大值12的機率會下降,並明顯低於接近中位數的結果機率,
其邏輯很簡單,一個骰子的情況下擲出點數最小值 1 的機率是 1 / 6,
但兩個骰子的情況下,擲出點數最小值 2 的機率會是 1 / 6 * 1 / 6,
因為我們需要兩個骰子同時都擲出點數最小值 1 ,結果才會是 2 。
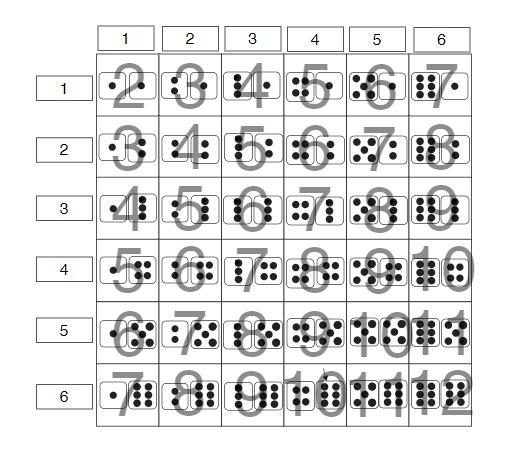
右圖裡是兩顆骰子的所有點數組合的可能性,
可以發現從最小點數2開始,當點數總量每增加1,
可能性的組合數量也會增加1,直到7為止,
點數總量再增加1,可能性的組合數量便開始下降。
有趣的是真實世界上大部分的亂數都是常態分佈的,
例如成績、身高、智商、體重等等,
因此在遊戲裡的如果和「演出」有關的內容,
會用到的亂數都會是常態分佈,
像是最常見的是射擊遊戲裡角色在射擊時的偏差便是其一。
所以我們其實也可以反推身高的分佈是常態分佈,
代表身高是由多於一種變數決定的,顯然小時候聽到的打球可以長身高,
幫助就算有也應該是不大的。
那如果我們想在程式碼裡實現符合常態分佈的亂數的話,
做法也和上述的例子相當,簡單而言就是用多於一個亂數函式,
並把其結果相加便能模擬出一個簡易的常態分佈亂數,
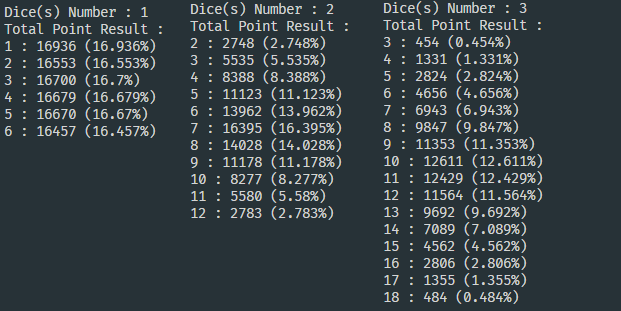
上圖中的是我用C++的rand()簡單模擬 n 顆六面骰子擲出100000次的結果,
源代碼在文尾,抱歉有點太趕,寫得有點亂,但應該多少看得懂的,
當只有一顆骰子時,每一個點的機率都是在1/6 ( 16.7% ) 上下,結果為均勻分佈。
但有兩顆骰子時,其結果的極端值出現機率比接近中位數的結果更低,開始呈現鐘型分佈,
到了三顆骰子時,鐘型分佈的兩端更接近了0。
而這就是一個在電腦上重現高斯分佈 / 常態分佈的方式。
暫時先分享這兩種亂數,未來有空再寫後續。